Fetch & Streams API
本篇將嘗試使用 Fetch Stream 實踐 XMLHttpRequest 的
abort和timeout,以及將大型資料以流(Stream)的方式獲取。
XMLHttpRequest
XMLHttpRequest 是在 AJAX(Asynchronous JavaScript And XML)開始盛行的當時,網頁工程師最主要用來獲取伺服器資料最主要的手段,直到 Fetch 釋出之後(2015 瀏覽器開始實裝),才開始被大家拋棄並遺忘。
其實在 Fetch 出現之前,可能也沒什麼人在裸寫 XMLHttpRequest,因為它的寫法稍嫌繁瑣、分散,不易管理,所以大部份人可能會使用 jQuery 的 $.ajax 或 Axios 這類將 XMLHttpRequest 封裝的比較方便的工具。
雖然話是這麼說,其實 XMLHttpRequest 也是有比 Fetch 方便的地方,例如 XMLHttpRequest 對於「取消請求」或「請求逾時」都有對應的 API 可以使用。
const xhr = new XMLHttpRequest(),
method = "GET",
url = "https://example.come.tw/";
xhr.open(method, url);
xhr.onabort = () => {
console.log("Request aborted");
};
xhr.send();
xhr.abort();
const xhr = new XMLHttpRequest(),
method = "GET",
url = "https://example.come.tw/";
xhr.timeout = 2000; // ms
xhr.open(method, url);
xhr.ontimeout = () => {
console.log("Request timeout");
};
xhr.send();
甚至是「請求的傳輸進度」這種功能,XMLHttpRequest 也有對應的事件可以使用。
const xhr = new XMLHttpRequest(),
method = "GET",
url = "https://example.come.tw/";
xhr.open(method, url);
xhr.onprogress = (event) => {
const { lengthComputable, loaded, total } = event;
if (lengthComputable) {
console.log(`Downloaded ${loaded} of ${total}`)
} else {
console.log(`Downloaded ${loaded}`);
}
};
xhr.send();
我先前有寫過另一篇文章來說明 Axios 是如何封裝 XMLHttpRequest 的
abort,有興趣的朋友可以看看 這裡。
AbortController
雖然反觀 XMLHttpRequest,Fetch 並沒有 abort 和 timeout 相關的 API,不過好在 Fetch 推出三年後也釋出了 signal 這個設定,讓我們可以使用 AbortController 來取消請求。若要實現請求逾時的話,也只要搭配 setTimeout 來使用即可。
const controller = new AbortController();
const { signal } = controller;
fetch("https://example.come.tw/", { signal });
controller.abort();
const controller = new AbortController();
const { signal } = controller;
fetch("https://example.come.tw/", { signal });
setTimeout(() => controller.abort(), 2000);
但是 Fetch API 並沒有提供類似 onprogress 這樣的事件,所以我們必須要找其他方法,而這個方法也就是本次要介紹的重點 - Fetch Stream。
Streams API
Streams API 可以讓我們以流(Stream)的方式獲取資料,若資料足夠龐大便會以數個片段的形式獲取資料,這樣的好處是可以節省記憶體的使用,並且能在資料還沒完全下載完之前就開始處理資料。而 Fetch API 中也是在 Response 中實裝了 Streams API。
除此之外,以流(Stream)形式獲取資料也可以透過管道(Pipe)的概念來處理資料,這樣的好處是可以將資料的處理分成多個步驟,讓程式碼更加模組化。
流的源頭
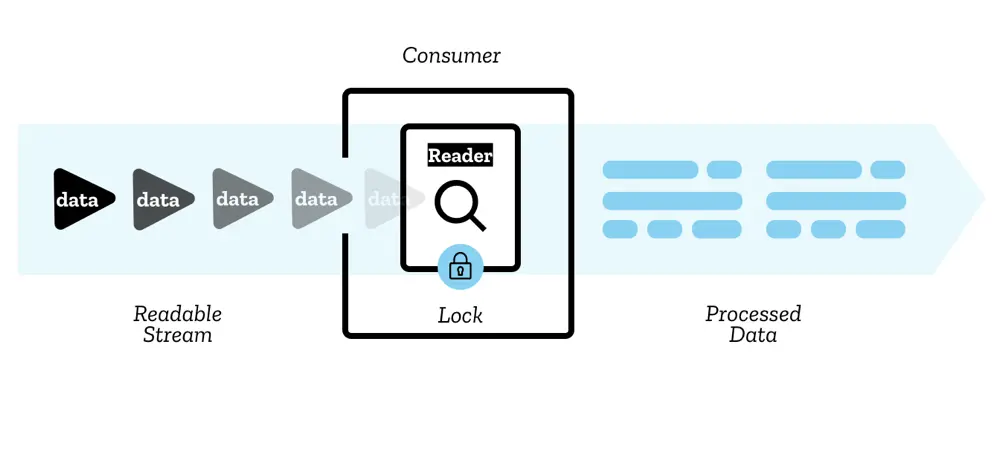
# ReadableStream.getReader
呼叫 fetch 時所回傳的 Promise,會 resolve 出一個 Response 實體,也就是平時常在 then 裡面簡稱的 res。一般常用的 res.json() 或 res.text() 其實都是來自於 Response,而我們要用的 Fetch Stream 也藏在其中。
在 Response 中還有一個 body 屬性,是一個 ReadableStream 的實體,而其中的 getReader 方法可以讓我們取得一個 ReadableStreamDefaultReader,只要呼叫它的 read 方法,就可以取得「流」的資料。
fetch("http://localhost:3000/")
.then((res) => {
/** @type { ReadableStreamDefaultReader } */
const reader = res.body.getReader();
let result = "";
return new Promise((resolve) => {
const pull = () => {
reader.read().then(({ done, value }) => {
if (done) return resolve(JSON.parse(result));
result += new TextDecoder("utf-8").decode(value);
pull();
});
};
pull();
});
})
.then((data) => {
console.log(data);
});
reader 類似於一個迭代器,每次使用 read() 都會回傳一個 Promise,你可以從中取得包含 done 與 value 的物件:
- done: 一個布林值,代表所有資料是否已經取得完畢。
- value: 一個
Uint8Array,代表這次取得的資料。
這邊我們用了一個遞迴的方式來呼叫迭代器,並且由於從 read 所得到的資料是 Uint8Array 的形式,所以我們需要用 TextDecoder 來將資料轉成字串。
請求的傳輸進度
像這樣一段一段的取得資料,可以說是完美的符合了「請求的傳輸進度」的需求,我們可以在每次取得資料的時候,去計算已經取得的資料量,並且印出來。
fetch("http://localhost:3000/")
.then((res) => {
const reader = res.body.getReader();
const contentLength = res.headers.get("Content-Length");
let loaded = 0;
const pull = () => {
reader.read().then(({ done, value }) => {
if (done) return console.log("Download complete");;
loaded += value.byteLength;
console.log(`Downloaded ${loaded} of ${contentLength}`);
pull();
});
};
pull();
});
這次我們從 Response Header 中拿到 Content-Length,並透過每次在 reader 中取得的資料來計算已經下載的資料量,這樣就可以實現「請求的傳輸進度」了。
# Response.clone
不過上面的範例中,只顧著把進度印出來卻沒有把資料存取下來,所以我們還得結合前兩段程式碼才可以,但其實也有一個更方便的辦法,那就是使用 Response.clone,這個方法可以複製一個 Response 物件,這樣就可以直接把資料回傳出去了。
fetch("http://localhost:3000/")
.then((res) => {
const returnRes = res.clone();
const reader = res.body.getReader();
const contentLength = +res.headers.get("Content-Length");
let loaded = 0;
const pull = () => {
reader.read().then(({ done, value }) => {
if (done) return console.log("Download complete");
loaded += value.byteLength;
console.log(`Downloaded ${loaded} of ${contentLength}`);
pull();
});
};
pull();
return returnRes.json();
})
.then((data) => {
console.log(data);
});
# ReadableStream.tee
除了 Response.clone 之外 Response.body 還有 tee() 這個方法,可以將 ReadableStream 複製成兩個,你可以想像它是把一個資料流分流成兩條了,而這兩條分流拿到的資料會是一樣的。
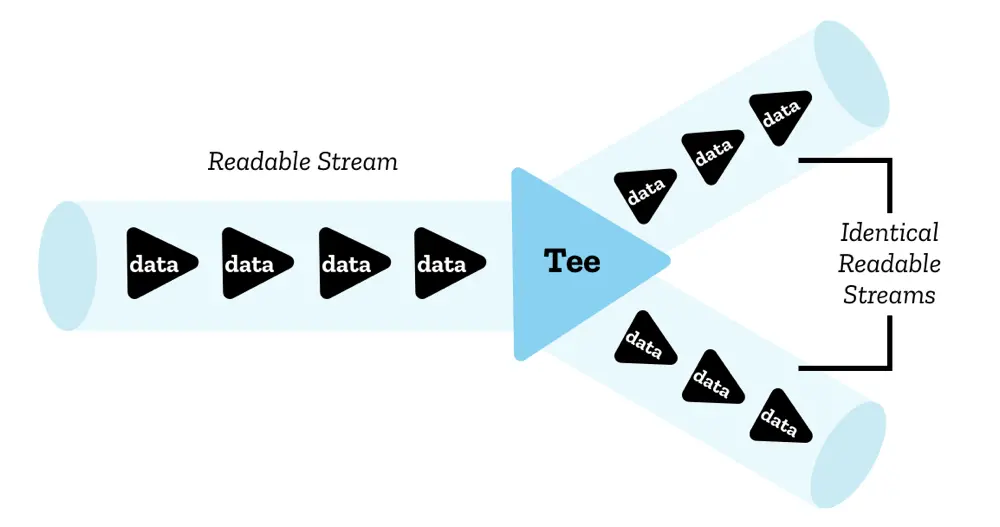
不過因為複製的是 ReadableStream,所以我們還是需要透過 Response 的建構子來建構一個新的 Response 實體,這樣才能夠使用 json 或 text 這類的方法。
fetch("http://localhost:3000/")
.then((res) => {
const [progressStream, returnStream] = res.body.tee();
const reader = progressStream.getReader();
const contentLength = +res.headers.get("Content-Length");
let loaded = 0;
const pull = () => {
reader.read().then(({ done, value }) => {
if (done) return console.log("Download complete");
loaded += value.byteLength;
console.log(`Downloaded ${loaded} of ${contentLength}`);
pull();
});
};
pull();
return new Response(returnStream, { header: res.headers }).json();
})
.then((data) => {
console.log(data);
});
到此為止,我們已經成功解決請求進度以及獲取資料的問題了,不過前面也有提到
AbortController出現的時間比較晚,那在此之前 Fetch API 又是如何實現取消請求的呢?其實也是可以使用 Fetch Stream 來完成的。
取消請求
# ReadableStream.cancel / ReadableStreamDefaultReader.cancel
在 Response.body 中還有一個 cancel 方法,它可以用來關閉一個流,而當一個流被關閉了,那對應的 Response 及其請求也就會被取消。所以我們嘗試這樣處理:
let aborter = null;
fetch("http://localhost:3000/")
.then((res) => {
aborter = () => {
res.body.cancel();
};
return res;
})
.then(res => res.json())
.then((data) => {
console.log(data);
});
aborter();
但卻沒有得到我們期望的結果,反而出現了以下錯誤:
TypeError: Failed to execute 'cancel' on 'ReadableStream': Cannot cancel a locked stream
不過沒關係,因為 ReadableStreamDefaultReader 也有 cancel 方法,它可以用來取消與此 reader 相關的流。所以我們嘗試這樣處理:
let aborter = null;
fetch("http://localhost:3000/")
.then((res) => {
aborter = () => {
const reader = res.body.getReader();
reader.cancel();
};
return res;
})
.then(res => res.json())
.then((data) => {
console.log(data);
});
aborter();
結果我們再次得到了錯誤,依然是告訴我們不能對一個已經被鎖定的流進行操作。
TypeError: Failed to execute 'getReader' on 'ReadableStream': ReadableStreamDefaultReader constructor can only accept readable streams that are not yet locked to a reader
不過我們依然不死心,既然 tee() 可以複製一個流,那我們就試試看能不能複製一個流,然後對這個複製出來的流進行取消。
let aborter = null;
fetch("http://localhost:3000/")
.then((res) => {
const [progressStream, returnStream] = res.body.tee();
aborter = () => {
const reader = progressStream.getReader();
reader.cancel();
};
return new Response(returnStream, { header: res.headers }).json();
})
.then((data) => {
console.log(data);
});
aborter();
這次終於沒有收到任何錯誤了,不過會發現我們的請求並沒有被取消, 因為我們取消的是 progressStream,而 returnStream 並沒有被取消,這個流依然在接收資料。
以上這些嘗試關閉流的方式都失敗了,原因在於一個流只能同時有一個處於活動狀態的 reader,當一個流被一個 reader 使用時,這個流就會被鎖定,當我們試圖對這個流進行操作時,就會出現錯誤。
但在第一個使用 Response.body.cancel 的範例中我們明明沒有使用任何 reader,怎麼流還是被鎖定了呢? 這是因為當我們使用 Response.json 或 Response.text 這類的方法時,這個方法會自動幫我們建立一個 reader 並且讀取資料,所以這個流就被鎖定了。
# new ReadableStream
所以我們無法使用 Fetch Stream 來實現取消請求嗎?其實不然,因為我們還有一個方法可以使用,那就是使用 ReadableStream 的建構子來建立一個新的流,用來代替原本的流「被鎖定」,並且還可以對這個新的流有額外的控制。
當我們要創建一個新的 ReadableStream 實體時,需要傳入一個設定對應生命週期 Callback 的物件,這個物件中有一個 start 方法,這個方法會在流開始時被呼叫,並且在被呼叫時會被傳入 controller 參數,這個參數是一個 ReadableStreamDefaultController 的實體,我們可以透過它來對流做一些內部操作。
const stream = new ReadableStream({
// 在實例建立時呼叫,並傳入一個流的內部控制器
start(controller) {
controller.close(); // 關閉流
controller.enqueue(chunk); // 將資料片段傳入流的佇列
controller.error(reason); // 從流的內部發出錯誤
},
// 在流的內部佇列未滿時,會重複呼叫這個方法
pull(controller) { ... },
// 在流將被取消時呼叫
cancel(reason) { ... }
});
下面我們就用這個方式創建一個「自訂流」①,並且從 res.body 這個「原始流」拿到 reader②,此時「原始流」會被這個 reader 鎖定,但這次 reader 是由我們全權掌控,從中取得的資料也會被做為「自訂流」的資料源片段。
接著暴露出一個 aborter 函式③,當中透過 reader.cancel() 來釋放「原始流」的鎖定,再者是利用 controller.error 在「自訂流」的內部發出錯誤,這樣我們就成功取消了這次的請求。
最後再用新的 Response 包裹這個「自訂流」④,這樣後續的 res.json() 鎖定的流就會是這個「自訂流」,而不是原本的「原始流」,如此就沒有鎖定衝突的問題了。
let aborter = null;
fetch("http://localhost:3000/")
.then((res) => {
const stream = new ReadableStream({ // 1
start(controller) {
let aborted = false;
const reader = res.body.getReader(); // 2
aborter = () => { // 3
reader.cancel();
controller.error(new Error("Fetch aborted"));
aborted = true;
};
const push = () => {
reader.read().then(({ value, done }) => {
if (done) {
if (!aborted) controller.close();
return;
}
controller.enqueue(value);
push();
});
};
push();
}
});
return new Response(stream, { headers: res.headers }); // 4
})
.then(res => res.json())
.then((data) => {
console.log(data);
})
.catch((err) => {
console.log(err);
});
aborter();
這邊我們已經成功實作出「取消請求」的功能,若要實作「請求逾時」的功能,只要搭配
setTimeout來使用即可。
另外為了更好理解有沒有使用 new ReadableStream 之間的差別,我也額外用圖像來表示一下:

管道串聯
最後要介紹的是前面有提到的,流(Stream)可以透過管道(Pipe)相互串接,讓資料處理可以步驟化,同時也不需要將所有資料都讀取完才能開始處理。
那首先要知道的是,每個管道鏈(Pipe Chain)的起點一定是一個 ReadableStream,而終點一定是一個 WritableStream,而中間的部分可以是 TransformStream。沒錯,除了 ReadableStream 之外,還有 TransformStream 和 WritableStream 這兩種流的類別。
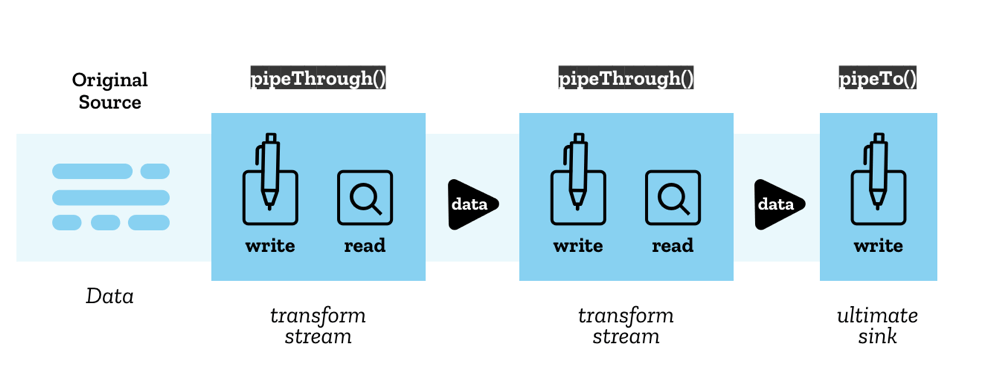
# new WritableStream
可寫入的流 WritableStream,這個流的建構子也是一樣,需要傳入一個設定對應生命週期 Callback 的物件,其中比較重要的是 write 屬性,這個屬性會在新的資料片段準備處理時呼叫,所以最主要的資料處理邏輯會寫在這裡。
const stream = new WritableStream({
// 在實例建立時呼叫,並傳入一個流的內部控制器
start(controller) {
controller.error(reason); // 從流的內部發出錯誤
},
// 在新的資料片段準備處理時呼叫
write(chunk, controller) { ... },
// 在所有資料處理完畢,流即將關閉時呼叫
close(controller) { ... },
// 在流被強制關閉時呼叫
abort(controller) { ... }
});
# WritableStream.getWriter / WritableStreamDefaultWriter.write
和 ReadableStream 一樣,WritableStream 也有一個對應的 getWriter 方法,可以取得一個 WritableStreamDefaultWriter 實體,其中的 write 方法可以用來將資料傳進流中開始進行處理。
const data = [0, 1, 0, 1, 0, 1];
let result = ""
const stream = new WritableStream({
write(chunk) {
const reverse = chunk === 0 ? 1 : 0;
result += reverse;
}
});
const writer = stream.getWriter();
data.forEach((value) => {
writer.ready.then(() => {
writer.write(value);
});
});
console.log(result); // 101010
這邊有一個非常簡單的範例,透過迴圈的方式將陣列中的數字用 writer.write 逐一傳入流中,並且在流的 write 方法中將數字進行處理。
不過需要注意的是,我們在呼叫 writer.write 時,可能會因為流的狀態而無法立即寫入,所以我們需要透過 writer.ready 來確保流已經準備好可以寫入。
# new TransformStream
作為連接起點的 ReadableStream 和終點的 WritableStream 之間的 TransformStream,它是一個既可以讀又可以寫的流,這個流的主要功能是將讀取的資料進行轉換,然後再寫入到流中。
一樣在建立實體時需要傳入一個設定對應生命週期 Callback 的物件,其中比較重要的是 transform 屬性,這個屬性會在新的資料片段可以進行從可寫入端到可讀取端的轉換時呼叫,所以最主要的資料處理邏輯會寫在這裡。
const stream = new TransformStream({
// 在實例建立時呼叫,並傳入一個流的內部控制器
start(controller) {
controller.enqueue(chunk); // 將資料片段傳入可讀取端的佇列
controller.error(reason); // 從流的內部發出錯誤
controller.terminate(); // 終止流
},
// 在新的資料片段可以進行從可寫端到可讀取端的轉換時呼叫
transform(chunk, controller) { ... },
// 在所有資料處理完畢,可寫入端即將關閉時呼叫
flush(controller) { ... }
});
注意!
TransformStream是由可寫入端與ReadableStream進行介接,由可讀取端與WritableStream進行介接,所以在其內部,資料是由可寫入端流進來,經過transform處理後再由可讀取端流出去。
# TransformStream.readable / TransformStream.writable
TransformStream 沒有任何方法,它暴露出來的只有他的可讀取端和可寫入端,這兩個端點可以讓我們取得一個 ReadableStream 和 WritableStream 實體,這樣我們就可以將 TransformStream 串接到其他流上。
const string = "Hello World";
const stream = new TransformStream({
transform(chunk, controller) {
console.log("Get Chunk:", chunk);
controller.enqueue(chunk); // 將資料片段傳入可讀取端的佇列
}
});
const transformWriter = stream.writable.getWriter();
for (const char of string) {
transformWriter.ready.then(() => {
transformWriter.write(char);
});
}
const transformReader = stream.readable.getReader();
transformReader.read().then(function dequeue ({ done, value }) {
if (done) return;
return transformReader.read().then(dequeue);
});
// Get Chunk: H
// Get Chunk: e
// ...
// Get Chunk: d
在上面這個範例中,我用利用 TransformStream.writable 拿取寫入端的 writer 將字串中的每個字元逐一寫入,然後在 transform 方法中將這些字元逐一傳入可讀取端的佇列,並且透過 TransformStream.readable 來拿取可讀取端的 reader 來讀取資料。這樣在 TransformStream 內部就會呼叫 transform 方法來處理資料。
# ReadableStream.pipeThrough / ReadableStreamDefaultReader.pipeTo
認識完所有的流之後,我們就可以開始串接流了,pipeThrough 和 pipeTo 就是用來將一個流接到另一個流的方法,其中 pipeThrough 只能接受 TransformStream 作為參數,pipeTo 則只能接受 WritableStream 作為參數。
const readableStream = new ReadableStream();
const transformStream1 = new TransformStream()
const transformStream2 = new TransformStream()
const writableStream = new WritableStream()
readableStream
.pipeThrough(transformStream1())
.pipeThrough(transformStream2())
.pipeTo(writableStream())
而可以用鏈式寫法的原因是因為 pipeThrough 會將它拿到的 TransformStream 的可讀取端回傳出來,讓下一個 TransformStream 或 WritableStream 可以繼續接上,而只要透過 Pipe 接上的流便會被鎖定住,至於為何會鎖住,我們可以自己嘗試實作 pipeThrough 和 pipeTo 就可以知道了。
function myPipeThrough(readableStream, transformStream) {
const reader = readableStream.getReader();
const writer = transformStream.writable.getWriter();
reader.read().then(function through({ done, value }) {
writer.ready.then(() => {
if (done) {
writer.close();
return;
}
writer.write(value);
})
reader.read().then(through);
});
return transformStream.readable;
};
function myPipeTo(readableStream, writableStream) {
const reader = readableStream.getReader();
const writer = writableStream.getWriter();
reader.read().then(function to({ done, value }) {
writer.ready.then(() => {
if (done) {
writer.close();
return;
}
writer.write(value);
})
reader.read().then(to);
});
};
可以看到我們在串接兩個流的時候,是個別取得對應的 reader 和 writer,然後透過 reader.read 和 writer.write 來進行資料的傳遞,這樣就可以了解為何串接流會被鎖定住了。這邊一樣放一張我畫的圖來讓大家更好理解:

這時候回想前面要實現取消請求的時候,為何
Response.body會被json()鎖定住了,我們可以合理懷疑這個方法內部應該是串接了一個TransformStream或WritableStream,所以我們無法對Response.body進行操作。
結尾
最後我們用前面所學,寫一個終極範例作為文章的結尾,希望今天的分享對大家有幫助,並且對 Fetch Stream 有更深一層的了解。
// 印出訊息用的 DOM 和函式
const logs = document.querySelector("pre");
const writeMsg = (msg) => {
logs.textContent += `${msg}\n`;
};
// 取消請求用的 flag 和函式
let aborted = false;
let streamAbort = () => {
console.log("not yet");
};
// 創建印出請求進度的流的工廠函式
const progressStreamFactory = (progressResponse) => {
let loaded = 0;
let cancel;
const total = progressResponse.headers.get("content-length");
const progressReader = progressResponse.body.getReader();
const stream = new ReadableStream({
start(controller) {
cancel = (msg) => {
progressReader.cancel(msg);
controller.error(msg);
};
progressReader.read().then(function log({ value, done }) {
if (done) {
if (!aborted) {
controller.close(value);
writeMsg("Download completed");
}
return;
}
loaded += value.length;
if (total === null) {
writeMsg(`Downloaded ${loaded}`);
} else {
const percentage = ((loaded / total) * 100).toFixed(2);
writeMsg(`Downloaded ${loaded} of ${total} (${percentage}%)`);
}
controller.enqueue(value);
return progressReader.read().then(log);
});
},
});
return [stream, cancel];
};
// 創建寫入流的工廠函式,他會將資料中的 "John" 文字替換成 "Mary",並在流關閉時印出 JSON
const writableStreamFactory = () => {
let result = "";
return new WritableStream({
write(chunk) {
const decoded = chunk.replaceAll("John", "Mary");
result += decoded;
},
close() {
console.log(JSON.parse(result));
},
abort(reason) {
writeMsg("Writer: " + reason);
},
});
};
// 創建用來返回資料的流的工廠函式
const returnStreamFactory = (returnResponse) => {
const returnReader = returnResponse.body.getReader();
let cancel;
const stream = new ReadableStream({
start(controller) {
cancel = (msg) => {
returnReader.cancel(msg);
controller.error(msg);
};
returnReader.read().then(function push({ value, done }) {
if (done) {
if (!aborted) controller.close(value);
return;
}
controller.enqueue(value);
return returnReader.read().then(push);
});
},
});
return [stream, cancel];
};
// 取得資料的函式
const getData = () => {
// reset
logs.textContent = "";
aborted = false;
streamAbort = () => {
console.log("not yet");
};
fetch("http://localhost:3000/")
.then((res) => {
return [res, res.clone()];
})
.then(([progressResponse, returnResponse]) => {
const [progressStream, progressStreamCancel] = progressStreamFactory(progressResponse);
const [returnStream, returnStreamCancel] = returnStreamFactory(returnResponse);
// 返回資料的流接了 TextDecoderStream 這個原生的 TransformStream,用來將 Uint8Array 轉成字串
// 然後再接上寫入流,將資料中的 "John" 文字替換成 "Mary",並在流關閉時印出 JSON
returnStream.pipeThrough(new TextDecoderStream()).pipeTo(writableStreamFactory());
streamAbort = () => {
if (aborted) return;
aborted = true;
const msg = "Download aborted";
progressStreamCancel(msg);
returnStreamCancel(msg);
writeMsg(msg);
};
});
};